



В настоящее время проводится активная модернизация системы высшего образования с целью повышения ее качества, в частности, значительное внимание уделяется увеличению доли научной составляющей в образовательном процессе, вопросам интеграции научной, инновационной и образовательной деятельностей, а также развитию научной деятельности в целом. Данный процесс сопровождается резким ростом требований ко всем участникам научно-образовательного процесса – преподавателям, магистрантам и аспирантам [11]. Среди основных требований можно выделить увеличение объема научных исследований в работе, число публикаций, активное участие в научных мероприятиях, количество полученных патентов и выигранных грантов [5]. Изменения, проводимые в деятельности вуза, требуют внедрения современных автоматизированных систем управления образовательными процессами и создания инфраструктуры для поддержки деятельности сотрудников и обучающихся. Эффективность реализации процессов научной деятельности определяется качеством решения следующих задач: поиск и обеспечение доступа к научно-исследовательским работам, выполняемым по схожим тематикам, своевременное информирование о проведении научных мероприятий и планирование участия в них, обеспечение возможности публикации полученных научных результатов в высокорейтинговых изданиях.
Постановка задачи
Для анализа процесса реализации научной деятельности обучающихся (магистранты и аспиранты) и преподавателей вуза была построена информационная модель верхнего уровня, представленная на рисунке 1. Данная модель описывает процессы взаимодействия участников и результаты их научной деятельности в информационной системе университета.
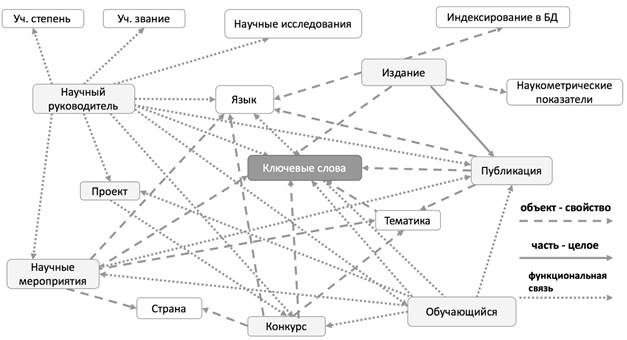
Рис. 1. Информационная модель научной деятельности
Анализ модели и предметной области позволил выделить основные проблемные области, связанные с принятием решений и поиском соответствующей информации:
· Выбор научного руководителя или обучающихся с учетом научных интересов.
· Поиск подходящих периодических изданий для публикации научных результатов.
· Выбор актуальных научных мероприятий для участия.
· Выбор конкурсов и грантов для финансирования проводимых научных исследований. В университете организована структура проектных менеджеров, которые регулярно отслеживают новости об открываемых конкурсах и фондах и отбирают те из них, которые могут заинтересовать преподавателей и обучающихся [12].
· Поиск значимых публикаций по заданным тематикам.
В построенной модели можно выделить следующие ключевые объекты:
· Научные руководители и обучающиеся – пользователи информационной системы.
· Научные мероприятия – конференции, конгрессы, семинары, круглые столы и прочие.
· Конкурсы – конкурсы, ориентированные на материальную поддержку преподавателей и обучающихся.
· Публикации – статьи, опубликованные в периодических издания.
· Издания – периодические издания.
В представленной модели, основные информационные объекты, связаны через ключевые слова, которые формируют профиль объекта или так называемую «область научных интересов». Использование методов частотного анализа и информационных технологий позволяют выполнять анализ связей между научными интересам участников, проводимыми исследованиями, актуальными конкурсами и мероприятиями. По результатам анализа формируются рекомендации для решения вопросов, озвученных выше.
Особенно важной задачей при использовании данного подхода является формирование научного профиля пользователя информационной системы и таких объектов как издания, публикации, конкурсы, мероприятия. Поскольку от полноты информации о профиле будет зависеть качество и точность формируемых рекомендаций, а следовательно эффективность развития научной деятельности вуза. Решение данной задачи имеет свои особенности, так как при формировании профиля используется множество источников информации, и при анализе информации необходимо правильно определять приоритеты тех или иных научных интересов.
В данной статье рассмотрен процесс формирования научного профиля для участника научно-исследовательской деятельности вуза, а также других связанных информационных объектов на примере научного профиля издания.
Формирование научного профиля пользователя
Формирование научных интересов пользователя в информационной системе университета происходит за счет самостоятельного ввода информации при заполнении личного профиля в информационной системе, а также автоматического сбора сведений о ключевых словах. Автоматический сбор сведений основывается на формализации и последующей интеграции информации из наукометрических баз данных, анализа поведения пользователей в информационной системе, его научно-практических результатов на основе методов частотного анализа и алгоритмов нечеткого поиска (см. рис. 2). Под наукометрическими базами данных понимают библиографические и реферативные базы данных, а также инструмент для отслеживания цитируемости научных статей [6].
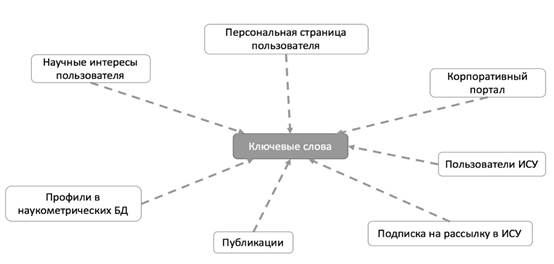
Рис. 2. Информационная модель научных интересов пользователя в информационной системе университета (ИСУ)
Автоматическое наполнение профилей ключевыми словами позволяет значительно расширить выборку, на которой в дальнейшем будет основываться инструмент предоставления рекомендаций по поставленным задачам, и повысить качество полученных рекомендаций.
Научные интересы пользователя – это множество его ключевых слов ![]() .
.
![]()
где ![]() – множество ключевых слов, указанных пользователем, а
– множество ключевых слов, указанных пользователем, а ![]() – множество ключевых слов, автоматически выбранных с учетом частоты их появления.
– множество ключевых слов, автоматически выбранных с учетом частоты их появления.
![]()
где ![]() – множество автоматически полученных ключевых слов,
– множество автоматически полученных ключевых слов, ![]() – частота появления ключевого слова
– частота появления ключевого слова ![]() ,
, ![]() – пороговое значение для частоты появления ключевого слова.
– пороговое значение для частоты появления ключевого слова.
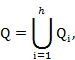
где ![]() – количество источников, на основании которых формируется множество
– количество источников, на основании которых формируется множество ![]() . Множество
. Множество ![]() формируется за счет:
формируется за счет:
· Посещения пользователем информационной системы. ![]() – множество ключевых слов, полученных по результатам посещения страниц, содержащих ключевые слова и тематики;
– множество ключевых слов, полученных по результатам посещения страниц, содержащих ключевые слова и тематики;
· Анализа схожих интересов между пользователями, посетившими одинаковые страниц. ![]() – множество ключевых слов пользователей со схожими интересами [3, 4];
– множество ключевых слов пользователей со схожими интересами [3, 4];
· Анализа тематик публикаций, автором которых является пользователь. ![]() – множество ключевых слов, полученных на основе анализа публикационной активности пользователя;
– множество ключевых слов, полученных на основе анализа публикационной активности пользователя;
· Анализа схожести интересов между соавторами публикаций, автором которых является пользователь. ![]() – множество ключевых слов соавторов публикаций пользователя;
– множество ключевых слов соавторов публикаций пользователя;
· Получения сведений о подписки пользователя на рассылку в информационной системе. ![]() – множество ключевых слов, указанных пользователям для получения рассылки в информационной системе;
– множество ключевых слов, указанных пользователям для получения рассылки в информационной системе;
· Анализа профиля пользователя в наукометрических базах данных. ![]() – множество ключевых слов пользователя, полученных из наукометрических баз данных.
– множество ключевых слов пользователя, полученных из наукометрических баз данных.

где ![]() – множество ключевых слов
– множество ключевых слов ![]() страницы,
страницы, ![]() – количество страниц. В статье рассматриваются страницы информационной системы, которые посещает пользователь.
– количество страниц. В статье рассматриваются страницы информационной системы, которые посещает пользователь.

где ![]() – множество ключевых слов пользователя
– множество ключевых слов пользователя ![]() ,
,![]() – множество пользователей, посетивших
– множество пользователей, посетивших ![]() – страницу, за исключением рассматриваемого пользователя,
– страницу, за исключением рассматриваемого пользователя, ![]() – мера Жаккара (
– мера Жаккара (![]() ), а
), а ![]() – пороговое значение схожести.
– пороговое значение схожести.

где ![]() – множество ключевых слов
– множество ключевых слов ![]() публикации,
публикации, ![]() – количество публикаций пользователя.
– количество публикаций пользователя.
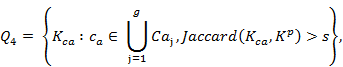
где ![]() – множество ключевых слов пользователя
– множество ключевых слов пользователя ![]() ,
,![]() – множество соавторов публикации
– множество соавторов публикации ![]() , за исключением рассматриваемого пользователя,
, за исключением рассматриваемого пользователя, ![]() – мера Жаккара, а
– мера Жаккара, а ![]() – пороговое значение схожести.
– пороговое значение схожести.
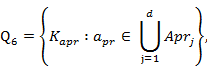
где ![]() – множество ключевых слов пользовательского профиля
– множество ключевых слов пользовательского профиля ![]() ,
, ![]() – множество авторских профилей наукометрической базы данных
– множество авторских профилей наукометрической базы данных ![]() для рассматриваемого пользователя,
для рассматриваемого пользователя, ![]() – количество наукометрических баз данных. В статье рассматриваются наиболее распространенные наукометрические базы данных и их идентификаторы авторских профилей:
– количество наукометрических баз данных. В статье рассматриваются наиболее распространенные наукометрические базы данных и их идентификаторы авторских профилей:
1. РИНЦ (российский индекс научного цитирования) – используется уникальный идентификатор SPIN-код [9];
2. Web of Science – самая авторитетная в мире база данных по научному цитированию института научной информации (Institute of Scientific Information - ISI) – используемый уникальный идентификатор ResearcherID [9];
3. Scopus – это крупнейшая в мире единая мульти дисциплинарная реферативная база данных, представляющая уникальную систему оценки частоты цитирования. Используемый уникальный идентификатор ORCID [9];
Авторский профиль из наукометрических базах данных в информационной системе представлен следующим образом:
![]()
где ![]() – множество публикаций авторского профиля,
– множество публикаций авторского профиля,![]() – идентификатор авторского профиля.
– идентификатор авторского профиля.
Анализ ключевых слов ![]() авторских профилей
авторских профилей ![]() , полученных из наукометрических баз данных, начинается с определения связей между пользователями информационной системы (авторами публикаций)
, полученных из наукометрических баз данных, начинается с определения связей между пользователями информационной системы (авторами публикаций) ![]() и наукометрическими базами данных. Множество авторов публикаций в информационной системе представлено следующий образом:
и наукометрическими базами данных. Множество авторов публикаций в информационной системе представлено следующий образом:
![]()
где ![]() – количество уникальных авторов.
– количество уникальных авторов.
Определение связей авторских профилей, полученных с наукометрических баз данных, и пользователями информационной системы является первостепенной задачей. Один из возможных подходов идентификации авторов публикаций из различных баз данных публикаций – это проведение анализа возможных внешних идентификаторов авторов и сопоставление их с внутренними (университетскими) идентификаторами [1]. Такие связи идентификаторов не всегда существуют, возникают новые авторские коллективы, автор может изменить фамилию, также в авторитетных базах данных авторы могут не иметь уникальный идентификатор, или один и тот же автор может быть связан с разными идентификаторами. В настоящее время в мире нет единого стандартизованного способа идентификации журнальных статей, авторов, их мест работы и др., несмотря на то, что в последние годы введены в действие немалое число различных идентификаторов [8]. При идентификации авторов большое значение имеет аффилиация. Некоторые авторы не указывают аффилиацию с университетом, что приводит к затруднению их идентификации. В случае работы с аффилиациями можно выделить следующие возможные варианты:
· Указана аффилиация – автор является сотрудником университета и указал ссылку на университет [1].
· Отсутствие аффилиации – автор является сотрудником университета и не указал ссылку на университет [1].
· Частичная аффилиация – автор является сотрудником университета и указал ссылку на несколько университетов [1].
Профиль автора ![]() в информационной системе имеет следующий вид:
в информационной системе имеет следующий вид:
![]()
где ![]() – множество ключевых слов
– множество ключевых слов ![]() – го автора,
– го автора, ![]() – множество публикаций,
– множество публикаций, ![]() – множество идентификаторов профилей в наукометрических базах данных,
– множество идентификаторов профилей в наукометрических базах данных,![]() – множество написаний автора на иностранном языке.
– множество написаний автора на иностранном языке.
![]()
где ![]() – количество уникальных иностранных написаний.
– количество уникальных иностранных написаний.
В качестве основного правила транслитерации была использована технология «OVIR of Russia regulations». В информационной системе университета предусмотрена возможность хранения различных вариантов транслитерации фамилии авторов, что позволяет использовать любые правила транслитерации и их комбинации. В связи с тем, что существуют различные методы транслитерации, не всегда возможно однозначно получить русскоязычное написание фамилии авторов. С учетом данного фактора возможно также и неоднозначное определение потенциальных авторов из базы физических лиц университета. Для обработки такой неоднозначности, необходима специализированная обработка данных [10]. В качестве обработки таких данных был разработан модуль анализа авторских коллективов публикаций авторских профилей ![]() , наиболее схожих по написанию с
, наиболее схожих по написанию с ![]() . Метод идентификации авторов заключается в определении потенциальных авторов
. Метод идентификации авторов заключается в определении потенциальных авторов ![]() по написанию
по написанию ![]() авторов статьи
авторов статьи ![]() с учетом научных коллективов и частоты их появления
с учетом научных коллективов и частоты их появления ![]() .
.
![]()
где ![]() – количество потенциальный сотрудников, подходящих написанию
– количество потенциальный сотрудников, подходящих написанию ![]() .
.
В данной статье научные коллективы представлены следующим образом:
![]()
где ![]() – соавторы по публикациям автора
– соавторы по публикациям автора ![]() ,
, ![]() – сотрудники подразделений в котором работает или работал
– сотрудники подразделений в котором работает или работал ![]() ,
, ![]() – обучающиеся под руководством
– обучающиеся под руководством ![]() ,
, ![]() – участники проектов, в которых участвует
– участники проектов, в которых участвует ![]() .
.
На рисунке 3 представлены возможные варианты идентификации авторов. Рассмотрим пример, представленный на рисунке 3а, более детально. У публикации на английском языке указаны два автора: Dzerzhauskaya T.A., Varenikov D.A. Для того чтобы идентифицировать сотрудников, являющихся авторами данной публикации, необходимо по иностранному написанию фамилии, имени и отчеству найти в базе данных соответствующих сотрудников [2]. Для рассматриваемого примера были найдены следующие совпадения:
1. Автор 1 - Dzerzhauskaya T.A. Для данного автора были найдены следующие схожие написания:
![]() – Dzerzhauskaya T.A. Данное написание указано у двух пользователей:
– Dzerzhauskaya T.A. Данное написание указано у двух пользователей:
![]() – Дзержавская Т.А.
– Дзержавская Т.А.
![]() – Державская Т.А.
– Державская Т.А.
![]() – Dziarzhauskaya T.A. Данное написание определено на основании анализа иностранного написания фамилий авторов, хранящихся в системе у одного сотрудника:
– Dziarzhauskaya T.A. Данное написание определено на основании анализа иностранного написания фамилий авторов, хранящихся в системе у одного сотрудника:
![]() – Дзиржавская Т.А.
– Дзиржавская Т.А.
2. Автор 2 - Varenikov D.A. Для данного автора было найдено одно написание:
![]() – Varenikov D.A.
– Varenikov D.A.
![]() – Вареников Д.А.
– Вареников Д.А.
Таким образом, однозначно определить связь Автора 1 с пользователем информационной системы невозможно, в отличие от Автора 2, для которого была найдена только одна связь с ![]() . Для того чтобы определить Автора 1, используется анализ авторских коллективов. С помощью проведенного анализа удалось определить, что из потенциальных авторов
. Для того чтобы определить Автора 1, используется анализ авторских коллективов. С помощью проведенного анализа удалось определить, что из потенциальных авторов ![]() ,
, ![]() ,
, ![]() только сотрудник
только сотрудник ![]() участвовал в авторском коллективе с сотрудником
участвовал в авторском коллективе с сотрудником ![]() .
.
Кроме того, возможен вариант неоднозначного определения соавтора после анализа авторских коллективов (см. рис. 3 б) и дополнительных сведений об авторах, в этом случае система оставляет данного автора нераспознанным и формирует подсказу для специалиста, который в дальнейшем будет обрабатывать публикацию. Чем больше авторов приведено в публикации и чем полнее они описаны, тем точнее происходит идентификация авторов на основе авторских коллективов (см. рис 3 в). На рисунке 3 г показан пример неоднозначного определения автора после транслитерации. В данном примере идентификация соавтора происходит только после анализа авторского коллектива и обработки специалистами публикации, на основании рекомендаций, представленных системой. Данный пример демонстрирует наполнение авторского профиля различными вариантами транслитерации его фамилии, что в дальнейшем позволяет идентифицировать его более точно [1].
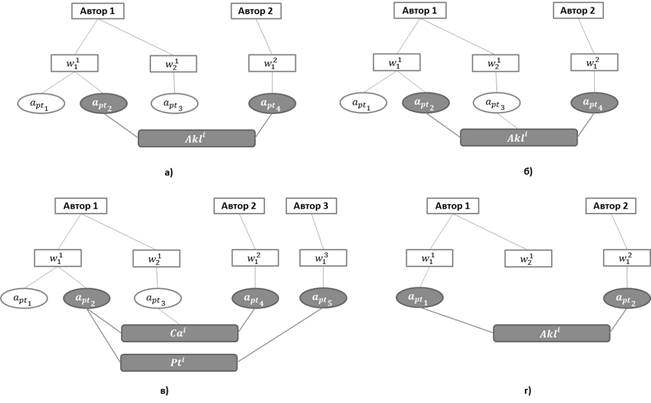
Рис. 3. Подход к идентификации авторов
Метод идентификации авторов, основанный на определении потенциальных авторов по написанию, с учетом научных коллективов и частоты их появления, позволил повысить качество определения и связи авторских профилей с наукометрическими базами данных и пользователями информационной системы. Рассмотренные подходы в дальнейшем будут применены к определению соответствия между пользователями информационной системы университета и их профилями в открытых научных Интернет-ресурсах [13].
Формирование профиля публикации
Информационная модель профиля публикации, представлена на Рис. 4. Одним из показателей профиля публикации являются ключевые слова ![]() . Данный показатель важен при формировании рекомендаций и поиска публикаций.
. Данный показатель важен при формировании рекомендаций и поиска публикаций.
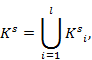
где ![]() – количество источников ключевых слов для периодического издания. Множество ключевых слов публикаций формируются на основе:
– количество источников ключевых слов для периодического издания. Множество ключевых слов публикаций формируются на основе:
· Множества ключевых слов, указанных авторами, – ![]() ;
;
· Множества ключевых слов, полученных из наукометрических баз данных, – ![]() . В наукометрических базах данных существует отдельное описание публикаций ключевыми словами и тематиками, соответствующим справочникам конкретной наукометрической базы;
. В наукометрических базах данных существует отдельное описание публикаций ключевыми словами и тематиками, соответствующим справочникам конкретной наукометрической базы;
· Множества ключевых слов периодического издания, к которому относится данная публикация, – ![]() .
.
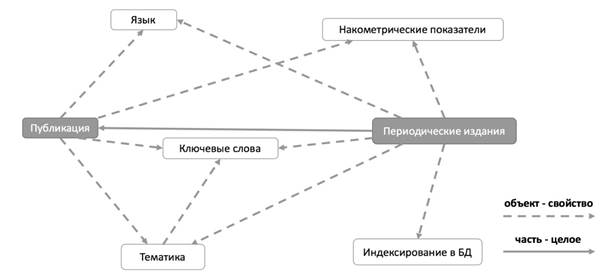
Рис. 4. Информационная модель профиля публикации
Формирования научных профилей конкурсов и научных мероприятий производится по схожей схеме и в статье не рассматриваются.
Заключение
В результате выполненной работы предложены подходы по автоматизации формирования научных профилей, которые позволили значительно расширить выборку, на основе которой в дальнейшем строятся рекомендации для пользователей информационной системы по выбору научного руководителя или обучающегося, научного мероприятия, грантов, публикаций и периодических изданий для публикации научных результатов. Полнота полученных данных позволила оптимизировать учет публикаций специалистами и, как следствие, повысить качество отчетных данных. Предложенные методы были реализованы в информационной системе управления университета.
Рецензенты:
Арустамов С.А., д.т.н., профессор, профессор кафедры проектирования и безопасности компьютерных систем, Университет ИТМО, г. Санкт-Петербург;
Коробейников А.Г., д.т.н., профессор, заместитель директора по науке СПбФ ИЗМИ РАН, г. Санкт-Петербург.