



Рассмотрим математическую модель поставленной задачи. Дан вектор X с размерностью 256, который представляет собой закодированное изображение известного распознаваемого символа. Также есть вектор Y с размерностью 10, который отражает требуемый результат распознавания, указывающий принадлежность символа к эталонному образцу. Необходимо найти весовую матрицу W, элементами которой являются вещественные числа в отрезке [0; 1], чтобы выполнялось равенство:
X*W = Y (1)
Необходимо осуществить настройку весовой матрицы W с помощью генетического алгоритма. В рамках решаемой задачи рассматриваемая матрица имеет следующую размерность: количество строк равняется 10, что представляет собой все символы, описывающие арабские цифры; количество столбцов определяется размером знакоместа, отводимого под каждый символ, 256 столбцов.
С точки зрения очевидности и простоты понимания следует каждый столбец матрицы весов рассматривать в качестве хромосомы, что приведет к наличию 256 хромосом, которые в совокупности будут отражать каждую особь. Однако при практической реализации гораздо удобнее использовать более простую структуру, хотя и менее наглядную. Это связано с тем, что довольно тяжело реализовать операции кроссинговера и мутации при наличии нескольких хромосом. Каждая особь в разрабатываемом генетическом алгоритме можно представить в виде только одной хромосомы, что значительно упростит программную реализацию на ЭВМ. Этого можно достичь следующим способом. Хромосома будет начинаться с первого столбца матрицы весов, и каждый следующий столбец будет просто добавляться в конец уже существующей «единой» хромосомы. Данный метод проиллюстрирован на рисунке 1.
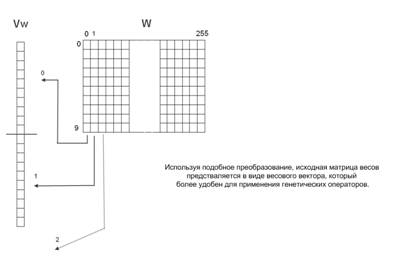
Рис. 1. Преобразование весовой матрицы W в вектор весов Vw.
Классический генетический алгоритм состоит из ряда наиболее важных этапов. Фактически данные этапы можно расположить в хронологическом порядке.
- ИНИЦИАЛИЗАЦИЯ - формирование исходной популяции.
- ОЦЕНКА ПРИСПОСОБЛЕННОСТИ - вычисление функции пригодности для каждой особи (в нашем случае хромосомы).
- СЕЛЕКЦИЯ - выборка на основе оценки приспособленности наиболее приспособленных хромосом, которым будет предоставлено право участия в операциях кроссинговера.
- КРОССИНГОВЕР - скрещивание двух особей.
- МУТАЦИЯ - намеренное искусственное изменение определенных генов в хромосомах особи.
- ФОРМИРОВАНИЕ НОВОЙ ПОПУЛЯЦИИ - снижение количества особей на основе оценки приспособленности вместе с выбором «наилучшей» особи.
- ПРОВЕРКА КРИТЕРИЯ ОСТАНОВКИ АЛГОРИТМА - если требуемое условие поиска достигнуто - выход, в противном случае - переход к этапу № 3.
- ИЗВЛЕЧЕНИЕ НАИЛУЧШЕГО РЕШЕНИЯ - наилучшим решением считается особь с максимальным значением функции пригодности.
Все описанные этапы являются абсолютно справедливыми в рамках решаемой задачи [1-3]. Практическая реализация первого шага любого генетического алгоритма в большинстве случаев представляет собой не что иное, как инициализацию случайным образом. Каждому гену любой хромосомы присваивается случайное значение из интервала допустимых значений. Соответственно, при настройке весовой матрицы W каждый ген получит генетическую информацию в виде случайного значения в отрезке [0; 1]. Программная реализация подобного метода инициализации является самой простой и имеет свои достоинства и недостатки. Достоинства заключаются в следующем.
- Не требуется применения дополнительных алгоритмов.
- Инициализация выполняется быстро и не загружает ЭВМ.
- Уменьшены шансы попадания в локальный оптимум.
В качестве недостатка можно отметить отсутствие в разрабатываемом алгоритме накопленных знаний о настраиваемых коэффициентах. Таким образом, в результате этапа инициализации имеется готовая популяция решений. Несмотря на абсурдность, можно говорить о наличии решения уже на первом этапе. После получения исходной популяции производится переход ко второму этапу - оценке приспособленности.
Оценка приспособленности особей в популяции заключается в вычислении значения функции пригодности для каждого члена популяции. И чем выше это значение, тем больше особь отвечает требованиям решаемой задачи. В рамках решаемой задачи весовая матрица есть часть нейронной сети, которая осуществляет распознавание образов. И соответственно генетический алгоритм выполняется на стадии обучения нейронной сети. Иными словами, необходимо привести весовую матрицу к такому виду, при котором ошибка распознавания эталонного образа будет минимальной. Таким образом, функция пригодности оценивает ошибку распознавания каждого эталонного образа, и чем меньше ошибка, тем выше значение функции пригодности. Задача состоит в минимизации ошибки распознавания. Для этого необходимо сравнить полученный вектор Y′ с эталонным образцом Y.
Этап селекции предусматривает выбор тех особей, генетический материал которых будет участвовать в формировании следующей популяции решений, т.е. в создании очередного поколения. Описываемый выбор производится согласно принципу естественного отбора, благодаря которому максимальные шансы имеют особи с наибольшими значениями функции пригодности. Различают достаточно большое множество методов селекции. Одним из самых известных и часто применяемых является метод «рулетки». Такое название интуитивно помогает понять его принципы. Каждая особь получает определенный сектор на «колесе», размер которого напрямую зависит от значения функции пригодности.
Отсюда вытекает, что чем выше значение функции пригодности, тем больше будет размер сектора на «колесе рулетки». Очевидно, что чем больше сектор, тем выше вероятность «победы» соответствующей особи. И, как следствие, вероятность выбора определенной особи оказывается пропорциональной значению ее функции приспособленности. Использование метода «рулетки» часто приводит к преждевременной сходимости алгоритма, которая заключается в том, что в популяции начинают доминировать лучшие особи, но не оптимальные. Спустя несколько поколений популяция практически полностью будет состоять из копий наиболее лучших особей. Однако весьма маловероятно, что достигнутое решение будет оптимальным, так как исходная популяция генерируется случайным образом и представляет собой лишь малую часть пространства поиска. Чтобы предотвратить преждевременную сходимость генетического алгоритма, используется масштабирование функции приспособленности. Масштабирование функции пригодности позволяет исключить ситуацию, когда средние и лучшие особи начинают формировать одинаковое число схожих потомков в следующих поколениях, что является крайне нежелательным явлением. Следует отметить, что масштабирование также предупреждает случаи, когда, несмотря на значительную неоднородность популяции, среднее значение функции приспособленности мало отличается от максимального. Итак, масштабирование функции приспособленности есть не что иное, как преобразование ее вида. Выделяют три основных преобразования: линейное, степенное и сигма-отсечение. В разработанном алгоритме используется преобразование сигма-отсечение.
![]() , (2)
, (2)
где а - малое число, как правило, от 1 до 5; ![]() - среднее значение функции приспособленности по популяции; δ - стандартное отклонение по популяции. В случае, когда полученные значения преобразованной функции будут отрицательны, их приравнивают к 0.
- среднее значение функции приспособленности по популяции; δ - стандартное отклонение по популяции. В случае, когда полученные значения преобразованной функции будут отрицательны, их приравнивают к 0.
Также можно в определенной степени модифицировать данный метод селекции или строить селекцию на основе синтеза сразу нескольких методов.
Следующим этапом генетического алгоритма является рекомбинация или кроссинговер. Каждый участок хромосомы особи заключает в себе определенную информационную нагрузку. Целью рекомбинации является получение такой комбинации промежутков хромосом, при которой особь будет представлять собой наилучшее из решений, возможное при текущем генетическом материале. В итоге основной задачей операции кроссинговера является получение в конечном итоге наиболее функциональных признаков, которые присутствовали в наборах исходных решений. Подобный механизм решения оптимизационных задач, в отличие от существующих методов, не осуществляет замену одного решения на другое, а получает новые возможные решения посредством обмена информацией между ними.
Скрещивание является наиболее важным оператором генетического алгоритма, так как именно с помощью оператора кроссинговера осуществляется обмен информацией между решениями. Потомки содержат в себе комбинацию специфических особенностей обоих родителей. Эффективность работы любого генетического алгоритма находится в прямой пропорциональной зависимости от эффективности операции кроссинговера. Кроме того, производительность генетического алгоритма зависит от успешности работы кроссинговера в первую очередь. В рамках решаемой задачи реализован упорядоченный оператор кроссинговера. Упорядоченный кроссинговер осуществляет поэтапное рутинное преобразование генетического материала, приближаясь к оптимальному решению.
На рис. 2 изображен процесс получения новых особей с использованием упорядоченного кроссинговера. Имеются две родительские хромосомы: Vw1 и Vw2. Генетическим материалом являются вещественные числа от 0 до 1. Упорядоченный кроссинговер работает следующим образом. Изначально случайным образом определяется «разрезающая точка». На следующем этапе первый потомок New_Vw1 наследует левую часть родительской хромосомы Vw1. Заполнение оставшихся генов новой хромосомы осуществляется за счет информации, хранящейся у второго родителя Vw2. Алгоритм просматривает хромосому Vw2 с самого начала и осуществляет извлечение генов, которые отличаются от генов, уже находящихся в потомке, более чем на величину e = 0,02. Малая величина e задается в алгоритме для определения «родства» генов. С каждым последующим шагом, а в особенности на завершающих этапах алгоритма, имеет смысл уменьшать значение этой величины для достижения более точных результатов. Аналогичная процедура выполняется при получении второго потомка New_Vw2. Второй потомок New_Vw2 наследует левую часть родительской хромосомы Vw2. Заполнение оставшихся генов получаемой хромосомы осуществляется за счет информации, находящейся у второго родителя Vw1.
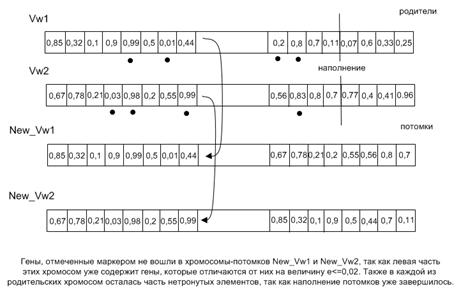
Рис. 2. Принцип работы упорядоченного кроссинговера.
Алгоритм производит анализ хромосомы Vw1 с первого гена и осуществляет упорядоченное извлечение генов, которые отличаются от генов, уже находящихся в потомке, более чем на величину e = 0,02. В результате работы каждого оператора скрещивания в популяции появляются две новые особи. Чтобы контролировать количество операций кроссовера используется коэффициент скрещивания Kk, определяющий долю производимых на каждой итерации потомков. Количество потомков определяется следующей формулой:
Countp = round(Sizep*Kk ) *2, (3)
где Sizep - размер популяции, Countp - количество получаемых потомков, round - операция округления.
Высокое значение коэффициента скрещивания Kk позволяет увеличить количество областей пространства поиска и уменьшает опасность попадания в локальный оптимум, однако слишком большое значение указанного параметра приведет к увеличению времени работы алгоритма, а также к чрезмерному исследованию малоперспективных областей поискового пространства.
Следующим этапом генетического алгоритма является мутация. Мутация есть изменение, которое приводит к проявлению качественно новых свойств генетического материала. Мутации происходят случайным образом и вызывают скачкообразные изменения в структуре генотипа.
В рамках решения оптимизационных задач наибольшее значение имеют генные мутации, которые в большинстве случаев затрагивают один или несколько генов. Мутация может выглядеть любым образом, будь то обмен генов своими позициями или копирование значения другого гена и т.д. В каждом генетическом алгоритме необходимо определиться с выбором вида мутации. В рассматриваемом генетическом алгоритме гены содержат в себе вещественные числа от 0 до 1. Согласно этому оператор мутации должен вносить конкретные изменения в генетический материал, т.е. изменять значения определенных генов, не опираясь на уже существующие гены. Суть разработанного оператора мутации состоит в следующем. В исследуемой хромосоме случайным образом выделяют также случайное количество генов. Коэффициент мутации Km определяет интенсивность мутаций. Он определяет долю генов, подвергнутых мутации на текущей итерации, в расчете на их общее количество. Если коэффициент мутации слишком мал, то получится ситуация, при которой множество полезных генов просто не будут существовать в популяции. В то же время использование большого значения коэффициента мутации приведет к множеству случайных возмущений и значительно увеличит время поиска. Потомки перестанут походить на родителей, алгоритм больше не будет иметь возможности обучаться на основе сохранения наследственных признаков. К выбранным генам применяют преобразование, которое вызывает изменение значения текущего гена на некоторую небольшую величину . Величина выбирается с таким учетом, чтобы после изменения значения i-го гена он находился в отрезке [0; 1].

Рис. 3. Случайная мутация на основе приращения.
На рис. 3 показано, как выполняется мутация, используя приращение . Гены с номерами 2 и 45 успешно получили новое значение, что приведет к изменению показаний функции пригодности мутирующей особи. В то время как мутация гена номер 6 оказалась неприемлемой и соответственно была проигнорирована. Использование мутаций на основе -приращения позволяет вносить в популяцию новый генетический материал. Это приведет к увеличению пространства поиска, что необходимо для эффективного поиска оптимума. Разумеется, имеет смысл воспользоваться классическим оператором мутации, в основе которого лежит случайное изменение порядка следования генов. Это также приводит к получению достаточно хороших результатов уже на ранних этапах работы генетического алгоритма. При решении рассматриваемой задачи также используется многоточечный оператор мутации. Алгоритм случайным образом в соответствии с коэффициентом интенсивности мутации выбирает несколько генов, значения которых далее меняются со значениями соседних генов. Работа классического многоточечного оператора мутации изображена на рис. 4.
Использование в одном алгоритме сразу нескольких видов оператора мутации позволяет осуществить эффективный поиск оптимального решения. Что позволяет в течение короткого промежутка времени получить неплохие результаты, а также выделить наиболее пригодные для изучения «окрестности решений».
Оператор мутации применяется к потомкам особей, получаемых после операции скрещивания. Особи с мутациями остаются в популяции до начала этапа «формирование новой популяции». Количество мутирующих особей определяется формулой:
![]() , (4)
, (4)
![]() ,
,
где Kmk - коэффициент классической мутации; Kmδ - коэффициент мутации на основе δ-смещения; Km - общий коэффициент мутации; Countm - количество особей, претерпевших мутацию; Countp - количество потомков; round - операция округления.
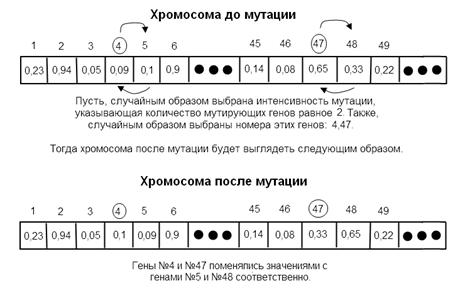
Рис. 4. Классический многоточечный оператор мутации.
Из формулы видно, что алгоритм позволяет в процентном соотношении регулировать баланс между классическим многоточечным оператором мутации и мутацией, основанной на d-приращении. С помощью данной функции можно подстраивать алгоритм под условия конкретной задачи. При увеличении доли использования классического оператора мутации увеличивается тщательность поиска в окрестности лучших решений на основе текущего генетического материала, а с увеличением доли мутаций, основанных на -приращении соответственно растет общее пространство поиска и происходит обновление генного состава популяции.
Следующим этапом разработанного генетического алгоритма является формирование новой популяции. Насколько сильно выросла численность популяции, определяется общим коэффициентом мутации Km и коэффициентом скрещивания Kk. В общем виде текущая численность популяции вычисляется по следующей формуле:
Sizep=Sizep+Countp+Countm, (5)
где Countp - количество полученного потомства, Countm - количество особей, полученных в результате мутаций, а Sizep - численность популяции.
Этап формирования новой популяции предназначен для того, чтобы вернуть численность популяции к ее исходному значению. Значение функций пригодности особей - родителей, которые уже находились в популяции, известно. Алгоритм осуществляет оценку пригодности особей - потомков, полученных в результате операции кроссинговера, а также оценку особей, которые были получены в результате работы оператора мутации. На основе полученных значений функции пригодности для каждой особи новой популяции производится удаление тех особей, у которых значения функции пригодности наименьшие. Алгоритм реализует данную задачу путем последовательного удаления особи с минимальным значением функции пригодности до тех пор, пока численность популяции не вернется к начальному значению. Количество «отмерших» особей вычисляется по формуле:
Countd=Countp+Countm, (6)
где Countd - количество «отмерших» особей, Countp - количество полученных потомков, Countm - количество особей, полученных с помощью оператора мутации.
На этапе формирования новой популяции также выполняется поиск наилучшего решения - той особи, у которой максимальное значение функции пригодности. Эта операция выполняется после того, как численность популяции установилась в исходную величину. После выбора наилучшей особи алгоритм передает управление процессом следующему этапу - проверке остановки алгоритма.
Определение критерия остановки генетического алгоритма напрямую зависит от специфики решаемой задачи и имеющихся сведений об объекте поиска. В большинстве оптимизационных задач, для которых известно оптимальное значение функции пригодности, остановку алгоритма можно организовать при достижении наилучшей особью этой величины, возможно с некоторой погрешностью. Решаемая задача на самом деле не располагает сведениями об оптимальном значении функции пригодности. Иными словами, алгоритм стремится максимизировать функцию пригодности с учетом того, что ошибка распознавания стремится к нулю. Поэтому в созданном алгоритме реализован механизм остановки поиска, основанный на отсутствии изменения функции пригодности наилучшей особи в течение определенного числа итераций, которое задается в качестве параметра генетического алгоритма. Кроме этого, алгоритм предусматривает остановку своей работы по истечении определенного числа итераций, которое также задается в качестве параметра. В том случае, если условие остановки выполнено, то алгоритм выдает в качестве оптимального решения то, которое представлено наилучшей особью, определенной на этапе формирования новой популяции. Если же условие не выполнено, то алгоритм передает управление этапу селекции.
Таким образом, в результате работы генетического алгоритма получен набор весовых коэффициентов, обеспечивающих корректную работу нейронной сети. Также стоит отметить тот факт, что использование специального оператора мутации позволило сократить время обучения сети. Для обучения было выбрано обучающее множество из 180 элементов. Время обучения на этом множестве с помощью описанного генетического алгоритма с использованием мутации на основе приращения, нечеткой сети Ванга-Менделя составило 2 мин. 50 сек., обучение с использованием алгоритма с применением классического многоточечного оператора мутации длилось 3 мин. 10 сек., а применение гибридного оператора мутации позволило сократить время обучения до 1 мин. 20 сек. Таким образом, полученный генетический алгоритм позволяет сократить время поиска наилучшего решения в рамках поставленной задачи.
КРОССИНГОВЕР - скрещивание двух особей.Библиографическая ссылка
Мищенко В.А., Коробкин А.А. ИСПОЛЬЗОВАНИЕ ГЕНЕТИЧЕСКИХ АЛГОРИТМОВ В ОБУЧЕНИИ НЕЙРОННЫХ СЕТЕЙ // Современные проблемы науки и образования. 2011. № 6. ;URL: https://science-education.ru/ru/article/view?id=5138 (дата обращения: 04.07.2026).