



Данные по экономическим показателям производства сельскохозяйственных предприятий Республики Дагестан отличаются своей неоднородностью.
Известно, что регрессионные модели корректно строить только по однородным группам данных, так как для объектов из неоднородных групп могут существовать различные закономерности изменения зависимых показателей при изменении тех или иных показателей-факторов. Иногда в таких случаях принято строить общую регрессионную модель для различных групп объектов, отличающихся своими количественными показателями. В таких моделях используются так называемые фиктивные переменные. В остальных случаях требуется предварительно классифицировать объекты на однородные группы, в рамках которых уже можно строить свои регрессионные уравнения [6; 7].
Целью настоящего исследования является разбиение исследуемой совокупности наблюдений на однородные группы (кластера) и построение моделей, позволяющих количественно оценить эффективность производства сельскохозяйственной продукции в Республике Дагестан. Для этого решена задача определения групп хозяйств с низким уровнем развития производства, которым требуется инвестиционная помощь, а также отбор сельхозорганизаций, которые могут стать примером умелого хозяйствования.
В исследовании использован кластерный анализ, представляющий собой специфическую методику классификации неоднородных статистических совокупностей. Его основное достоинство - возможность объединять в группы разнородные объекты по нескольким показателям. Выбор метрики или меры близости является узловым моментом исследования, от которого в основном зависит окончательный вариант разбиения объектов на классы при данном алгоритме разбиения. Наиболее распространенными алгоритмами кластерного анализа являются иерархические процедуры, принцип работы которых состоит в последовательном объединении (разбиении) групп элементов сначала самых близких (далеких), а затем все более отдаленных (близких) друг от друга [4-6].
В данном исследовании в качестве мер различия выбраны евклидово расстояние, манхэттенское расстояние и расстояние Махаланобиса. А в качестве методов кластерного анализа выбраны метод ближней связи, метод Уорда и метод k-средних Мак-Куина [1; 6].
Метод ближней связи начинает процесс классификации с поиска и объединения двух наиболее похожих объектов в матрице сходства. На следующем этапе находятся два очередных наиболее похожих объекта, и процедура повторяется до полного исчерпания матрицы сходства.
Особенность метода Уорда состоит в том, что основанием для помещения объекта в кластер является не близость двух объектов в каком-либо смысле, в зависимости от меры сходства, а минимум дисперсии внутри кластера при помещении в него текущего классифицируемого объекта.
Принцип метода k-средних сводится к некоторому, возможно случайному, исходному разбиению множества объектов на заданное число кластеров с последующим отнесением остальных объектов к ближайшим кластерам, пересчету новых «центров тяжести» кластеров и продолжению описанной процедуры, пока не будет получено некоторое оптимальное разбиение. При этом изменчивость объектов минимизируется внутри кластеров и максимизируется между кластерами.
В качестве объекта исследования выступают сельскохозяйственные предприятия РД [2]. Основными видами их продукции являются виноград, зерновые культуры, мясо и молоко. Анализ проведен по объему производства каждого из названных видов продукции, урожайности, площади зерновых культур и виноградников, надоям молока на 1 корову, среднесуточному привесу, а также количеству скота по данным хозяйств за 2009 и 2010 гг.
Кластерный анализ осуществлен с помощью дополнительного модуля AtteStat для электронных таблиц Excel [1].
Реализация кластерного анализа с помощью различных метрик и правил объединения кластеров позволила сделать вывод о целесообразности разбиения предприятий по производству винограда на два кластера. Судя по значениям показателей предприятий второго кластера, можно заключить, что эти предприятия являются крупными предприятиями РД по производству винограда. Средние показатели этого кластера составили: 31495 ц по валовому сбору, 410 га - по площади виноградников. Для предприятий первого кластера эти показатели составили соответственно 3139 ц и 128 га.
На рис. 1 приведены графики, выражающие зависимость объема производства винограда от урожайности по двум кластерам. Как видно из графиков, тренд, отражающий изменение объема произведенного винограда во втором кластере, гораздо выше другого.
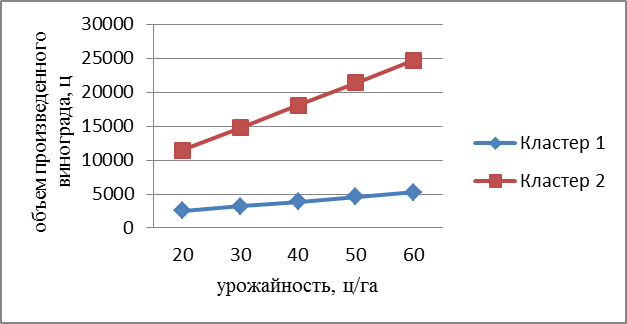
Рис. 1. Зависимость объема произведенного винограда от урожайности для различных кластеров.
Математическая запись уравнений регрессии соответственно для первого и второго кластеров имеет следующий вид:
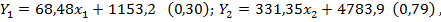
где Y1, Y2- объемы произведенного винограда соответственно в каждом кластере, x1 и x2 - урожайности винограда соответственно в каждом кластере. В скобках указаны коэффициенты детерминированности, показывающие степень тесноты корреляции между объемом производства винограда и его урожайностью.
Кластерный анализ предприятий по производству молока проведен по данным 83 предприятий за 2009-2010 гг. В соответствии с полученными результатами хозяйства целесообразно разделить на 2 кластера. Во второй кластер вошли 20 предприятий, и они являются крупными предприятиями РД по производству молока, т.к. средний объем произведенного молока во втором кластере составляет 2834 ц, в то время как в первом кластере оно составляет всего 438 ц. У сельхозпредприятий, вошедших во второй кластер, больше число коров на одно хозяйство. Среднее поголовье коров во втором кластере составляют 123 головы, а в первом кластере - 31 голова. Следовательно, предприятия, входящие в состав первого кластера, являются предприятиями с низким уровнем производства молока.
Уравнения зависимости валовых надоев молока от надоя на 1 корову для различных кластеров таковы:
![]()
где Y1, Y2 - валовой надой молока соответственно в каждом кластере, x1 и x2 - надои на 1 корову соответственно в каждом кластере.
В результате анализа предприятий по валовому сбору зерна также были получены два кластера: первый кластер, характеризующийся низким уровнем валового сбора зерна, и второй кластер, куда входят крупные зерновые предприятия РД. При этом каждый дополнительный гектар площади зерновых культур увеличивает валовой сбор зерна на 4,5 ц в первом кластере и на 3,2 ц - во втором. Эти выводы сделаны из следующих уравнений: ![]() где Y1 и Y2 - валовой сбор зерна для первого и второго кластеров соответственно; x1 и x2 - площадь зерновых культур для каждого из двух кластеров.
где Y1 и Y2 - валовой сбор зерна для первого и второго кластеров соответственно; x1 и x2 - площадь зерновых культур для каждого из двух кластеров.
Кластерный анализ предприятий по производству зерновых культур выявил, что подавляющая часть предприятий второго кластера, характеризующегося высокими валовыми сборами зерновых, являются хозяйствами Кизлярского района РД. Эти хозяйства имеют все предпосылки для создания зернового кластера. Напомним, что М. Портер [3] представляет кластер как «группу географически соседствующих взаимосвязанных компаний и связанных с ними организаций, действующих в определенной сфере и характеризующихся общностью деятельности и взаимодополняющих друг друга». Из предприятий по производству винограда во второй кластер вошли предприятия Дербентского и Каякентского районов РД.
Анализ хозяйств по производству мяса показал целесообразность их разбиения на три кластера. В первый кластер вошли 43 хозяйства, во второй - 30, а в третий - 7.
Средний объем производства мяса в третьем кластере составляет 599 ц, во втором - 134,4 ц (средний уровень развития мясного животноводства), а в третьем - 27,4 ц, т.е. характеризуется низким уровнем развития мясного животноводства. Уравнения зависимости объема произведенного мяса от среднесуточного привеса таковы: ![]() где Y1, Y2, Y3 - объем произведенного мяса для каждого из трех кластеров соответственно;
где Y1, Y2, Y3 - объем произведенного мяса для каждого из трех кластеров соответственно; ![]() - среднесуточный привес для каждого из трех кластеров соответственно.
- среднесуточный привес для каждого из трех кластеров соответственно.
На рис. 2 видно, что по хозяйствам первого и третьего кластеров изменение среднесуточного привеса не оказывает значительного влияния на объем производства мяса, а по хозяйствам второго кластера наблюдается снижение объема мяса при увеличении среднесуточного привеса.
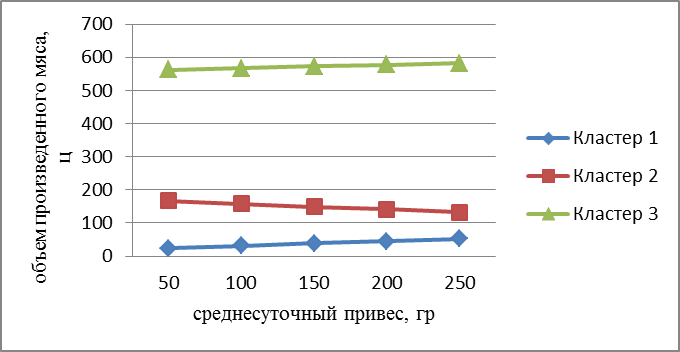
Рис. 2. Зависимость объема произведенного мяса от среднесуточного привеса для различных кластеров.
Выводы
Таким образом, кластерный анализ позволяет значительно повысить адекватность регрессионных моделей. Поэтому до применения аппарата корреляционно-регрессионного анализа следует разбить всю совокупность имеющихся исходных данных на однородные классы и решать поставленную задачу отдельно для каждого из них.
Рецензенты
- Кутаев Ш.К., д.э.н., старший научный сотрудник, Институт социально-экономических исследований Дагестанского научного центра РАН, г. Махачкала.
- Алиев М.А., д.э.н., профессор кафедры экономической теории, Дагестанский государственный педагогический университет, г. Махачкала.
Библиографическая ссылка
Адамадзиев К.Р., Касимова Т.М. ОЦЕНКА ЭФФЕКТИВНОСТИ ПРОИЗВОДСТВА СЕЛЬСКОХОЗЯЙСТВЕННОЙ ПРОДУКЦИИ РЕСПУБЛИКИ ДАГЕСТАН НА ОСНОВЕ КЛАСТЕРНОГО АНАЛИЗА // Современные проблемы науки и образования. – 2012. – № 3. ;URL: https://science-education.ru/ru/article/view?id=6242 (дата обращения: 19.04.2024).