



Введение
Системы поддержки принятия решений в социально-экономических сферах, использование систем компьютерной диагностики на основе структурного распознавания образов, экспертные системы, обработка документов – это далеко не полный перечень задач, для которых можно эффективно использовать аппарат символьных вычислений, под которым понимается обработка символьной информации в целом, включая компьютерную алгебру. Вместе с тем акселерация вычислений в существенной степени зависит от аппаратной платформы, поэтому в данной работе в прикладном аспекте рассматриваются устройства быстрых продукционных вычислений. Названный новый класс устройств быстрых продукционных вычислений не требует изменения существующей платформы массовой вычислительной техники, используемой в современных учреждениях, и применяется в качестве периферийных процессоров-акселераторов с невысокой стоимостью. Доля символьных вычислений в медицинских учреждениях, в издательской деятельности и т.п. значительна, поскольку обработка числовой информации не является доминирующей. Например, в медицине обрабатывается большой объем электронных документов, таких как формуляры, карты больных, заключения и т.д.
Цель данной статьи заключается в создании новых инструментальных средств информационных технологий на основе продукционной парадигмы.
Принципы реализации устройств символьных вычислений
Основные положения теории обработки символьной информации приведены в работах [1–5], а важные для данной статьи положения теории нормальных модифицированных алгоритмов рассматриваются в [1; 4].
Рассмотрим продукцию с алфавитными переменными, которая представлена словом, имеющим следующий вид:
agyb®dyga, (1)
где символ «®»– метасимвол, не принадлежащий рабочему алфавиту, отделяющий образец от модификатора; g, y – алфавитные переменные; «a» и «b» и «d» – конкретные символы рабочего алфавита.
Алфавитные переменные конкретизируются значениями символов из соответствующих им позиций в обрабатываемом слове (ОС). Необходимо уточнить, что алфавитные переменные в продукциях могут принимать любые значения из алфавита либо значения из его определенной части.
Введем продукцию с переменной длиной образца и модификатора, которая представлена словом, имеющим следующий вид:
а#b®d#g, (2)где символ «#» в образце означает то, что в ОС между символами «а» и «в» имеется цепочка символов переменной длины, в том числе и пустая. Этот же символ «#» в модификаторе означает то, что он может формироваться как из символов «b» и «g», так и из цепочки, полученной при обнаружении позиции вхождения образца в ОС. Для того чтобы осуществить поиск позиции вхождения образца в ОС и модификацию, аналогичную формуле (2), необходимо применить эквивалентный алгоритм из продукции с алфавитными переменными. Такой алгоритм представляется конечным списком слов, имеющим следующий вид:
agyβ b®dgyβ g ,
agy b®dgy g ,
ag b®dg g . . (3)
Из алгоритма (3) следует: чтобы обнаружить продукцию, в которой образец совпадет с фрагментом ОС, необходимо затратить время для выбора соответствующей продукции в процессе работы алгоритма.
Правила работы продукционных устройств с одним и двумя блоками памяти для ОС, реализующих продукцию канонического вида [4], описаны в работах [1]. Структурная схема устройства с двумя блоками памяти для ОС представлена на рисунке 1.
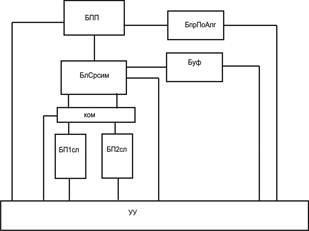
Рис. 1. Структурная схема устройства с двумя блоками памяти для обрабатываемого слова: УУ – устройство управления; БПП – блок памяти продукций;
БП1сл, БП2сл – блоки памяти обрабатываемого слова;
Ком – коммутатор; БлСрсим – блок сравнения символов;
Буф – буфер; БпрПоАлг – блок перехода по продукциям в алгоритме.
Работа с одной продукцией алгоритма заключается в просмотре (сопоставлении) посимвольно ОС и образца продукции для обнаружения позиции его вхождения в ОС. Такое сопоставление осуществляется в блоке «БлСрсим» (рис. 1) во время перезаписи символов ОС из одного блока памяти в другой, причем считанный символ образца записывается во второй блок. В случае обнаружения позиции вхождения образца в ОС на место совпавшего фрагмента во второй блок памяти ОС записывается модификатор.
Работа продукционных алгоритмов выполняется по модифицированной схеме, которую можно представить конечным списком продукций следующего вида:
М1:γi®βj :М2 , (4)
где γi, βj – цепочки символов заданного рабочего алфавита, несущие тот же смысл, как и у продукции (1), М1, M2 – метки (натуральные числа) перехода на определенные номера продукции из списка; М1 – если продукция не обнаружила своего вхождения при просмотре слова, М2 – соответственно если обнаружила, такой алгоритм заканчивает свою работу если продукция имеет специальный признак заключительной продукции, или не срабатывает последняя в списке продукция.
Коммутатор в данном устройстве необходим для того, чтобы «менять» блоки памяти по принципу выдающей на обработку ОС блок памяти и принимающей ОС при работе по продукционному алгоритму (перезапись из одного блока в другой, а затем обратно).
Результаты работы устройства на примере двух продукций, имеющих одинаковую длину образца и разные длины модификаторов.
abg®cccc , (5)
abg®cc . (6)
На рисунке 2 схематически представлены два блока памяти для ОС.
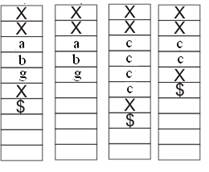
Рис. 2. Схемы расположения символов ОС в блоках памяти для устройства с двумя блоками памяти: а – блок памяти «БП1сл», из которого считывается ОС; б – блок памяти «БП2сл», в который записывается ОС, соответствует моменту обнаружения позиции вхождения образца в ОС; в – блок памяти «БП2сл», окончательный результат обработки для продукции вида (4) при образце по длине меньше модификатора; г – блок памяти «БП2сл», окончательный результат обработки для продукции вида (5) при образце большем по своей длине, чем модификатор.
Продукция (1), реализуемая на устройстве с двумя блоками памяти для ОС, представляется словом, имеющим следующий вид:
a**b$d*2*1a$, (7)
где символ «*» в образце является признаком алфавитной переменной; «$» – признаки конца образца и модификатора; символы «*1» и «*2» в модификаторе – порядковый номер алфавитной переменной в образце.
Продукция (1), с ограничением на алфавит, будет иметь следующий вид:
a{ C1C2}*d$β$, (8)
где «a, d» – конкретные символы рабочего алфавита; символ «*» – алфавитная переменная; скобки {} указывают на область изменения значений алфавитной переменной (любой символ алфавита, который располагаются в нем между символами «C1» и «C2»); β – модификатор.
Продукцию (2) можно представить словом, имеющим следующий вид:
а#b$®d#g$, (9)
где символ «#» в образце означает то, что в ОС между символами «a» и «b» может находиться цепочка символов любой конечной длины; «$» – признаки конца образца и модификатора.
Сопоставление для символа «*» всегда завершается успешно, а символ ОС, соответствующий этой переменной, записывается как во второй блок памяти ОС, так и в буфер. Замена совпавшей части ОС с образцом осуществляется из символов модификатора продукции, считываемого из блока памяти продукций и записываемого посимвольно во второй блок памяти. Если в модификаторе встречается символ «*», то из блока памяти продукций считывается следующий символ модификатора «2», являющийся порядковым номером, по которому в буфере записан символ из ОС, конкретизирующий алфавитную переменную образца. Этот символ из буфера затем записывается следующим во второй блок памяти ОС вслед за предыдущим.
Структурная схема устройства с одним блоком памяти для ОС представлена на рисунке 3.
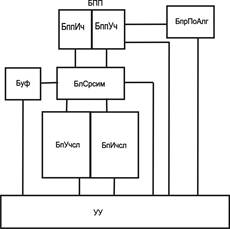
Рис. 3. Структурная схема устройства с одним блоком памяти для ОС: УУ – устройство управления; БПП – блок памяти продукций (Ич – информационная часть, Уч – управляющая часть); ПлПсл – блок памяти ОС (Ич – информационная часть, Уч – управляющая часть);
БлСрсим – блок сравнения символов; Буф – буфер.
Рассмотрим структурную организацию варианта устройства, при котором ОС размещено в одном блоке памяти (рис. 3).
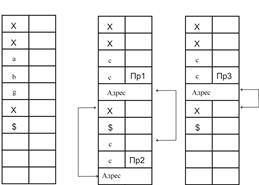
Рис. 4. Схемы расположения ОС в памяти для устройства с одним блоком памяти ОС: а – исходное слово; б – окончательный результат, случай, когда длина модификатора больше длины образца; в – окончательный результат, случай, когда длина модификатора меньше длины образца.
Блок памяти для продукций и ОС двухбайтные (информационный и управляющий байты). Признаки концов слова образца и слова модификатора представлены дополнительным управляющим байтом, который записывается в памяти продукции над позициями их последних символов соответственно.
Размещение слова в памяти при различных длинах образцов и модификаторов представлены рис 4. Если длина модификатора больше длины образца, то в управляющей части слова модификатора ставится специальный признак в позиции, равной длине образца, уменьшенной на единицу (рис. 4), продукция (1), признак Пр1. Другой признак Пр2 ставится в конце модификатора (рис. 4), продукция (1), признак Пр2. Если длина модификатора меньше длины образца, то в конце образца в управляющем байте ставится специальный признак Пр3, показывающий, что это признак окончания модификатора (рис. 4), продукция (2), признак Пр3.
Теперь из блока памяти продукций считываются символы модификатора со своими управляющими байтами и записываются в блок памяти ОС на место символов совпавшего фрагмента образца в ОС. Если в управляющем байте определяется один из признаков Пр1, Пр2 или Пр3, то он будет записан в управляющий байт ОС, а в следующие по порядку два байта в ОС будет записан адрес перехода (рис. 4). Если длина модификатора больше длины образца, то таких адресов в ОС будет два: первый адрес – переход в свободный фрагмент памяти, второй адрес – возврат на символ ОС, следующий за позицией окончания совпавших фрагментов ОС и образца (рис. 4б). Если длина модификатора меньше длины образца, то такой адрес один (рис. 4в).
Для реализации на устройстве с одним блоком памяти для ОС продукция (1) будет иметь следующий вид (таблица 1)
Таблица 1 – Побайтное представление продукции
|
|
|
|
1 |
|
|
|
1 |
|
|
|
1 |
|
|
2 |
1 |
|
|
а |
* |
* |
в |
в |
* |
* |
а |
Первые две строки таблицы 1 представляют управляющие байты (четыре бита – первая, четыре бита – вторая строки). Третья строка (байт) – символы продукции. Признак «1» в первой строке означает конец образца или модификатора. В этом варианте реализации устройства появляется новая возможность определять равные значения разных алфавитных переменных при их конкретизации при работе продукции. Признак «1» во второй строке в образце указывает, что первая и вторая алфавитные переменные имеют равные значения при их конкретизации. Цифровые символы в позиции записи модификатора в таблице 1 обозначают номера алфавитных переменных в образце, которые считываются из буфера в процессе модификации. Продукция (1) с ограничением на алфавит для этого устройства будет иметь следующий вид (таблица 2).
Таблица 2 – Побайтное представление продукции
|
|
|
|
|
1 |
1 |
|
|
|
|
2 |
2 |
|
|
|
|
|
|
а |
C1 |
C2 |
* |
d |
β |
|
|
Признак «1» в верхней строке обозначает конец образца и конец модификатора. Признак «2» в следующей строке указывает на то, что код символа, соответствующий «*», может быть любым в диапазоне кодов между C1 и C2 .
При аппаратной реализации продукций вида (2) на устройстве с одним блоком памяти для ОС (рис. 2) с дополнительным байтом для каждого ее символа организация памяти продукций иллюстрируется таблицей 3.
Таблица 3 – Побайтное представление продукции
|
|
|
1 |
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
а |
# |
в |
b |
# |
g |
|
|
|
|
Две первые строки таблицы 3 по аналогии с таблицей 1 представляют собой управляющие байты (четыре бита – первая строка, четыре бита – вторая). Третья строка (байт) – символы рабочего алфавита продукции.
Поиск вхождения образца в ОС выполняется посимвольно, как и в устройстве с двумя блоками памяти (рис. 1). В этом устройстве появляется новая возможность определять равенство значений алфавитных переменных за счет введения дополнительного (управляющего) байта в памяти продукций и, как следствие, изменять обработку символа слова, что позволит вводить специализированные продукции для обработки специализированных текстов.
Заключение
Таким образом, предложены способы реализации продукций с переменными для двух вариантов устройств. Результаты, полученные в данной работе, могут быть использованы в дальнейшем при разработке процессоров обработки символьной информации в качестве периферийных устройств-акселераторов. Это дает возможность существенно повысить скорость обработки символьной информации в системах подготовки и обработки документов в социально-экономических сферах.
Рецензенты:
Зотов И.В., д.т.н., профессор кафедры «Информационные системы и технологии», Юго-Западный государственный университет, г. Курск.
Дегтярев С.В., д.т.н., профессор кафедры «Информационные системы и технологии», Юго-Западный государственный университет, г. Курск.
Библиографическая ссылка
Корольков О.Ф., Апальков В.В., Чаплыгин А.А., Королькова В.О. БЫСТРАЯ ОБРАБОТКА СИМВОЛЬНОЙ ИНФОРМАЦИИ В СИСТЕМАХ УПРАВЛЕНИЯ ДОКУМЕНТАМИ И ПРИНЯТИЯ РЕШЕНИЙ: РЕАЛИЗУЮЩИЕ УСТРОЙСТВА // Современные проблемы науки и образования. – 2012. – № 6. ;URL: https://science-education.ru/ru/article/view?id=8049 (дата обращения: 20.04.2024).