



В практике принятия решений по рациональной типизации учебных ученических или студенческих групп, выявлению существенных различий между группами, оценке динамики в группах и т.п., часто используются показатели, выраженные бинарным признаком для индивидуального случая и обобщающими долями (процентными долями) в группе, имеющие смысл успеваемости или результативности тестов, контрольно-оценочных мероприятий. Данные такого характера часто бывают доступны в открытых источниках или получаются в результате несложной обработки других данных, собираемых для иных целей. Кроме очевидных ситуаций полного совпадения групповых показателей, либо ситуаций, когда одна из групп продемонстрировала проявление (отсутствие) нужного признака во всех индивидуальных случаях, может быть поставлен вопрос о статистике различий в групповых показателях. Иными словами, если в групповых показателях есть разница, то правомерен вопрос о том, является ли она типичной для сопоставляемых групп данного объёма или свидетельствует о существенных различиях контингента, отсюда и привлечение статистических приёмов для решения этого вопроса.
При общем рассмотрении обозначенной проблемы выявляются следующие особенности, которые должны быть учтены в процедурах сопоставления групп. Во-первых, произвольность выбора того, что при принятии решений считается индивидуальным «успехом», проявление признака в индивидуальном испытании или его отсутствие, налагает требование независимости вычислительных процедур и их результатов от такого выбора. Во-вторых, если вероятности появления и отсутствия признака в индивидуальном случае примерно равны, то ожидается более широкий симметричный естественный разброс значений эмпирических долей, чем при экстремальных вероятностях, близких к крайним значениям 0 и 1 (100%). В-третьих, для сравнительно больших групп ожидается усреднение влияния случайных факторов, которое нужно учитывать. В-четвёртых, в практическом исследовании сопоставляться могут и группы примерно одинакового объёма, и существенно разного объёма.
Применение к данной проблеме подходов, основанных на использовании центральной предельной теоремы (утверждение о том, что «z-критерий» для долей имеет нормальное распределение), представлено в ряде источников [1-3], но представляется сомнительным, когда анализируются группы небольшого (порядка десяти индивидуальных случаев) или среднего (порядка тридцати индивидуальных случаев) объёма, из-за явной дискретности распределений. По опыту, даже при сопоставлении групп объёмом по 90–150 индивидуальных случаев, довольно часто проявляются эффекты, связанные с дискретностью распределений, а это уже объёмы, характерные для диссертационных исследований в педагогике. Кроме того, существенная асимметрия распределений долей при малых (0–20%) и больших (80–100%) случаях фиксации «успехов» приводит к применению специальных статистических критериев непараметрического характера. В качестве такого специального метода в [4] предлагается использовать критерий Смирнова, но чаще в отечественной медицине [5-7], психологии и педагогике [8; 9] рекомендуется (с рядом ограничений на объёмы обследованных групп) использовать «угловое преобразование» эмпирических долей 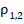 , предложенное P. Фишером
, предложенное P. Фишером 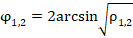 , и вычисление обобщающей величины, учитывающей объёмы обеих обследованных групп
, и вычисление обобщающей величины, учитывающей объёмы обеих обследованных групп 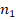 и
и 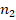 , по формуле
, по формуле
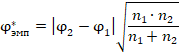
Для сравнения применяется единая шкала (не совпадающая со стандартным нормальным распределением) критических значений (квантилей накопительной функции распределения), отражающих вероятность того, что эмпирические доли 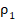 и
и 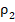 , реализованные в группах, при одинаковых шансах проявления признака в них, продемонстрируют значение
, реализованные в группах, при одинаковых шансах проявления признака в них, продемонстрируют значение 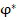 меньше указанного:
меньше указанного: 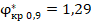 ,
, 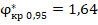 ,
, 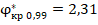 и т.д. При больших значениях
и т.д. При больших значениях 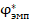 , превышающих критические, предлагается, c такой доверительной вероятностью, признать различие эмпирических долей существенным, нетипичным при единых шансах проявления признака успешности в двух группах на уровне значимости 10%, 5% или 1% соответственно.
, превышающих критические, предлагается, c такой доверительной вероятностью, признать различие эмпирических долей существенным, нетипичным при единых шансах проявления признака успешности в двух группах на уровне значимости 10%, 5% или 1% соответственно.
По описанной процедуре, -критерий выглядит привлекательным: лёгкий способ вычисления главной статистики, компактная таблица критических значений, легко достигаемых в практике применения критерия, применимость к малым и большим группам, очень мягкие ограничения (по описанию критерия, при объёмах групп больше пяти случаев возможны любые сопоставления). Расчётная процедура обладает хорошей симметрией, при замене долей и на их дополнения 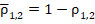 значение гарантированно сохраняется. Скорость возрастания функции
значение гарантированно сохраняется. Скорость возрастания функции 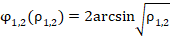 существенно возрастает при приближении к экстремальным значениям
существенно возрастает при приближении к экстремальным значениям 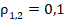 или
или 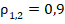 по сравнению с точкой симметрии
по сравнению с точкой симметрии 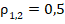 . Значения возрастают в связи с объёмами сопоставляемых групп, что удобно для планирования дальнейших исследований по предыдущим. Обзор практики использования -критерия в научных работах психолого-педагогического характера показывает, что
. Значения возрастают в связи с объёмами сопоставляемых групп, что удобно для планирования дальнейших исследований по предыдущим. Обзор практики использования -критерия в научных работах психолого-педагогического характера показывает, что 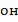 используется для сопоставления групп разного объёма (например, в [10-12]). Для сопоставления групп примерно одинакового малого объёма около 20 индивидуальных случаев критерий использован в [13], но выборки такого объёма редко являются основанием для научного обобщения, хотя могут возникать в педагогической практике, и их не следует игнорировать. Наиболее часто в сопоставлении используются группы, соответствующие примерно одной (в [14-16]) или двум-трём (в [17-19]) академическим учебным группам. Есть примеры ([20] и др.) применения -критерия для сопоставления групп объёмами порядка одной сотни индивидуальных случаев.
используется для сопоставления групп разного объёма (например, в [10-12]). Для сопоставления групп примерно одинакового малого объёма около 20 индивидуальных случаев критерий использован в [13], но выборки такого объёма редко являются основанием для научного обобщения, хотя могут возникать в педагогической практике, и их не следует игнорировать. Наиболее часто в сопоставлении используются группы, соответствующие примерно одной (в [14-16]) или двум-трём (в [17-19]) академическим учебным группам. Есть примеры ([20] и др.) применения -критерия для сопоставления групп объёмами порядка одной сотни индивидуальных случаев.
Принципиальные препятствия к широкому применению -критерия видятся в следующем. Во-первых, неясное происхождение таблицы критических значений, которая переходит из источника в источник около полувека. Во-вторых, неясность в способности критерия различить группы с исходно различными показателями, то есть отсутствие сведений о мощности рассматриваемого критерия, в зависимости от величины этого различия, асимметрии доли и объёмов групп. В-третьих, неуверенность в том, что критерий действительно настолько универсален в отношении асимметричности долей и объёмов сопоставляемых групп, как это декларируется.
Цель исследования
Проверка -критерия в контролируемых модельных абстрактных ситуациях в контролируемых условиях, c заранее заданными вероятностями проявления «успешности» в сопоставляемых группах, имеющих объёмы, характерные для научных и практических исследований в педагогике; разработка и обоснование практических рекомендаций по его прикладному применению.
Материал и методы исследования
Аналитическое моделирование. При объёмах сопоставляемых групп и все возможные доли 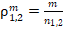 , где
, где 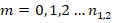 , а их вероятности реализации в испытании определялись по точной формуле Бернулли
, а их вероятности реализации в испытании определялись по точной формуле Бернулли 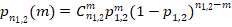 . Заполнение двумерной таблицы позволяет вычислить вероятности всех комбинаций долей через произведение вероятностей этих долей, как независимых событий. Параллельно во второй двумерной таблице такой же размерности вычисляются все возможные значения , они могут дублироваться в таблице, и им приписываются соответствующие вероятности реализации долей из первой таблицы. Далее в третьей таблице сохраняются и суммируются только вероятности из первой таблицы для ограниченных сверху произвольно заданным уровнем
. Заполнение двумерной таблицы позволяет вычислить вероятности всех комбинаций долей через произведение вероятностей этих долей, как независимых событий. Параллельно во второй двумерной таблице такой же размерности вычисляются все возможные значения , они могут дублироваться в таблице, и им приписываются соответствующие вероятности реализации долей из первой таблицы. Далее в третьей таблице сохраняются и суммируются только вероятности из первой таблицы для ограниченных сверху произвольно заданным уровнем 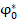 из второй таблицы – так получается точная теоретическая вероятность того, что в испытании не превысит . Для более сложной обработки, значения сортируются по возрастанию, вероятности дублирующихся значений складываются, и результаты моделирования могут быть представлены в виде накопительной (интегральной) функции распределения случайной величины . Для расчётов могут быть использованы электронные таблицы или пакеты прикладных программ для технических расчётов (независимо от платформы), а производительности современных персональных компьютеров достаточно для точного моделирования любой ситуации с объёмами сопоставляемых групп до 300 индивидуальных случаев. Для получения всех результатов для этой статьи использован табличный процессор MS Excel.
из второй таблицы – так получается точная теоретическая вероятность того, что в испытании не превысит . Для более сложной обработки, значения сортируются по возрастанию, вероятности дублирующихся значений складываются, и результаты моделирования могут быть представлены в виде накопительной (интегральной) функции распределения случайной величины . Для расчётов могут быть использованы электронные таблицы или пакеты прикладных программ для технических расчётов (независимо от платформы), а производительности современных персональных компьютеров достаточно для точного моделирования любой ситуации с объёмами сопоставляемых групп до 300 индивидуальных случаев. Для получения всех результатов для этой статьи использован табличный процессор MS Excel.
Имитационное моделирование. Случайные величины с заранее заданными вероятностями «успеха» многократно разыгрываются и группируются в пакеты объёмом или , имитируя реализацию испытания. Такие пары «выборок» сопоставляются с помощью -критерия, проявляя закономерности распределения случайной величины и позволяя сравнить заранее заданные вероятности «успеха» с картиной распределения после реализации в выборке и обработки в виде накопительной (интегральной) функции распределения. Применялось только для ситуации сопоставления групп по 10 индивидуальных случаев (парное сопоставление групп разыгрывалось более трёх тысяч раз) и показало неплохое совпадение с точным теоретическим распределением, но потребовало расчётов в количестве, на десятичный порядок большем, чем аналитическое моделирование.
Применение 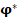 -критерия в контролируемых условиях (основные результаты исследования)
-критерия в контролируемых условиях (основные результаты исследования)
Для аналитического получения распределения в паре сопоставляемых групп по 10 случаев с заранее заданными вероятностями «успеха» 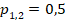 составим двумерную таблицу (табл. 1) возможных значений долей , соответствующих этим парам значений и (с помощью формулы Бернулли для независимых испытаний и произведения вероятностей) вероятностей появления такого сочетания в обследовании. Аналогично моделируются другие ситуации, различающиеся заранее заданной вероятностью «успеха» в группах постоянного объёма.
составим двумерную таблицу (табл. 1) возможных значений долей , соответствующих этим парам значений и (с помощью формулы Бернулли для независимых испытаний и произведения вероятностей) вероятностей появления такого сочетания в обследовании. Аналогично моделируются другие ситуации, различающиеся заранее заданной вероятностью «успеха» в группах постоянного объёма.
Таблица 1
Данные для распределения величины
(сопоставление двух групп по 10 случаев, заранее заданная вероятность 50%) –
в скобках указана вероятность появления такого частного значения
|
|
0 |
0,1 |
0,2 |
0,3 |
0,4 |
0,5 |
0,6 |
0,7 |
0,8 |
0,9 |
1 |
|
|
|
|
0 (0,001) |
0,64 (0,010) |
0,93 (0,044) |
1,16 (0,117) |
1,37 (0,205) |
1,57 (0,246) |
1,77 (0,205) |
1,98 (0,117) |
2,21 (0,044) |
2,5 (0,01) |
3,14 (0,001) |
|
0 |
0 (0,001) |
0 (0) |
1,44 (0) |
2,07 (0) |
2,59 (0) |
3,06 (0) |
3,51 (0) |
3,96 (0) |
4,43 (0) |
4,95 (0) |
5,59 (0) |
7,02 (0) |
|
0,1 |
0,64 (0,010) |
1,44 (0) |
0 (0) |
0,63 (0) |
1,15 (0,001) |
1,62 (0,002) |
2,07 (0,002) |
2,52 (0,002) |
2,99 (0,001) |
3,51 (0) |
4,15 (0) |
5,59 (0) |
|
0,2 |
0,93 (0,044) |
2,07 (0) |
0,63 (0) |
0 (0,002) |
0,52 (0,005) |
0,99 (0,009) |
1,44 (0,011) |
1,89 (0,009) |
2,36 (0,005) |
2,88 (0,002) |
3,51 (0) |
4,95 (0) |
|
0,3 |
1,16 (0,117) |
2,59 (0) |
1,15 (0,001) |
0,52 (0,005) |
0 (0,014) |
0,47 (0,024) |
0,92 (0,029) |
1,37 (0,024) |
1,84 (0,014) |
2,36 (0,005) |
2,99 (0,001) |
4,43 (0) |
|
0,4 |
1,37 (0,205) |
3,06 (0) |
1,62 (0,002) |
0,99 (0,009) |
0,47 (0,024) |
0 (0,042) |
0,45 (0,051) |
0,9 (0,042) |
1,37 (0,024) |
1,89 (0,009) |
2,52 (0,002) |
3,96 (0) |
|
0,5 |
1,57 (0,246) |
3,51 (0) |
2,07 (0,002) |
1,44 (0,011) |
0,92 (0,029) |
0,45 (0,051) |
0 (0,061) |
0,45 (0,051) |
0,92 (0,029) |
1,44 (0,011) |
2,07 (0,002) |
3,51 (0) |
|
0,6 |
1,77 (0,205) |
3,96 (0) |
2,52 (0,002) |
1,89 (0,009) |
1,37 (0,024) |
0,9 (0,042) |
0,45 (0,051) |
0 (0,042) |
0,47 (0,024) |
0,99 (0,009) |
1,62 (0,002) |
3,06 (0) |
|
0,7 |
1,98 (0,117) |
4,43 (0) |
2,99 (0,001) |
2,36 (0,005) |
1,84 (0,014) |
1,37 (0,024) |
0,92 (0,029) |
0,47 (0,024) |
0 (0,014) |
0,52 (0,005) |
1,15 (0,001) |
2,59 (0) |
|
0,8 |
2,21 (0,044) |
4,95 (0) |
3,51 (0) |
2,88 (0,002) |
2,36 (0,005) |
1,89 (0,009) |
1,44 (0,011) |
0,99 (0,009) |
0,52 (0,005) |
0 (0,002) |
0,63 (0) |
2,07 (0) |
|
0,9 |
2,5 (0,01) |
5,59 (0) |
4,15 (0) |
3,51 (0) |
2,99 (0,001) |
2,52 (0,002) |
2,07 (0,002) |
1,62 (0,002) |
1,15 (0,001) |
0,63 (0) |
0 (0) |
1,44 (0) |
|
1 |
3,14 (0,001) |
7,02 (0) |
5,59 (0) |
4,95 (0) |
4,43 (0) |
3,96 (0) |
3,51 (0) |
3,06 (0) |
2,59 (0) |
2,07 (0) |
1,44 (0) |
0 (0) |
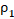
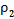
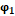
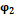
Для имитационного моделирования (многократного розыгрыша) сопоставления двух групп с заранее заданными вероятностями «успеха» бинарная случайная величина разыгрывалась более шести тысяч раз и из этих результатов были сформированы три тысячи «выборок», характеризуемые долей «успешных» опытов. На рисунке 1 представлены результаты сравнения распределений величины , полученные аналитически, с помощью имитации (многократного розыгрыша) и табличных данных из [8] – красной линией.
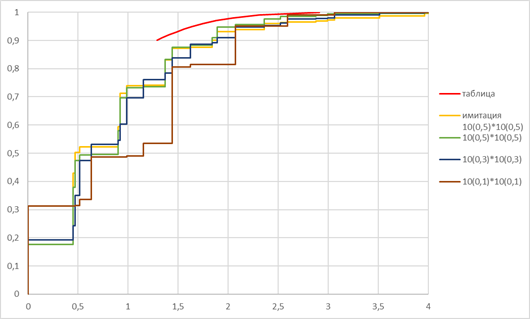
Рис. 1. Сравнение накопительных функций распределения величины 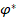 с заранее заданными совпадающими вероятностями «успеха»
с заранее заданными совпадающими вероятностями «успеха» 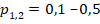 в группах по 10 индивидуальных случаев
в группах по 10 индивидуальных случаев
По результатам сравнения, распределение значений в имитационном моделировании для рассмотренной частной ситуации неплохо совпало с аналитической зависимостью (желтая и зелёная линии на рис. 1 выше), но табличные значения не выдерживают сравнения с расчётными, при их использовании доверительная вероятность принимаемых решений оказывается гораздо ниже декларируемой, и наибольшие расхождения с табличными значениями наблюдаются при экстремальной заранее заданной вероятности «успеха» 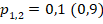 . Сравнительные данные для групп с одинаковой заранее заданной вероятностью «успеха» в индивидуальном случае приведены в п.п. 2 – 4 таблицы 2.
. Сравнительные данные для групп с одинаковой заранее заданной вероятностью «успеха» в индивидуальном случае приведены в п.п. 2 – 4 таблицы 2.
Таблица 2
Сопоставление результатов, ожидаемых при применении -критерия
|
№ |
Сопоставляемые группы по 10 случаев |
Значение |
||
|
1,29 |
1,64 |
2,31 |
||
|
1 |
Любые – по таблице критических значений из [8] |
90% |
95% |
99% |
|
2 |
Одинаковая индивидуальная вероятность «успеха» 0,5 |
74% |
88% |
96% |
|
3 |
Одинаковая индивидуальная вероятность «успеха» 0,3 (0,7) |
76% |
88% |
95% |
|
4 |
Одинаковая индивидуальная вероятность «успеха» 0,1 (0,9) |
53% |
81% |
95% |
|
5 |
Индивидуальные вероятности «успеха» 0,3 (0,7) и 0,5 |
57% |
74% |
87% |
|
6 |
Индивидуальные вероятности «успеха» 0,1 (0,9) и 0,3 (0,7) |
47% |
62% |
76% |
|
7 |
Индивидуальные вероятности «успеха» 0,3 и 0,7 |
22% |
39% |
58% |
|
8 |
Индивидуальные вероятности «успеха» 0,1 (0,9) и 0,5 |
19% |
33% |
49% |
Для качественной оценки мощности -критерия используем некоторые ситуации, когда заранее заданные вероятности и, соответственно, проявленные доли «успеха» ожидаются различными, наиболее яркие результаты сравнения соответствуют экстремальным значениям заранее заданной вероятности «успеха» 0,1 (0,9) в одной из групп и приведены далее на рисунке 2 и выше в таблице 2.
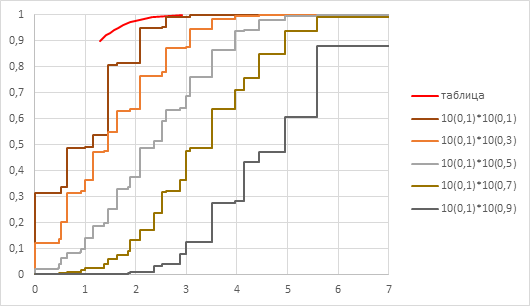
Рис. 2. Накопительная функция распределения величины для заранее заданной вероятности «успехов» 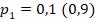 в одной из групп и разной вероятности «успеха» в другой группе
в одной из групп и разной вероятности «успеха» в другой группе
Визуально графики различаются друг от друга гораздо сильнее, чем графики для совпадающих заранее заданных вероятностей «успеха», но при практическом применении -критерия приходится различать ситуации не по «развёрнутой» картине накопительных функций распределения, а по единственному значению , и если диапазоны наиболее вероятных значений в двух ситуациях существенно пересекаются, то различить эти ситуации может оказывается затруднительным. Например (п. 4 таблицы 2), если значение окажется равным 1,29, то его можно считать типичным и для ситуации с заранее заданными равными индивидуальными вероятностями «успеха», так как примерно с равной вероятностью может быть и больше, и меньше этого значения. Но (п. 6 таблицы 2) и при заранее заданном различии 0,2 в индивидуальных вероятностях «успеха» это значение тоже типично, то есть сохраняется неопределённость в выборе одной из этих альтернатив. Однако основной алгоритм принятия решения в процедуре применения -критерия (с учётом необходимой поправки к табличным значениям) приводит здесь к утверждению «данных за существенное расхождение долей не получено», что не противоречит приведённым в таблице 2 точным результатам. Если рассмотреть возможное значение 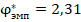 , или немного больше, то такое значение придётся признать нетипично высоким для совпадающих долей (пп. 2 – 4 таблицы 2), но оно остаётся достаточно типичным для случая с заранее заданными разными вероятностями «успеха» в двух группах этого объёма. Далее, при значениях
, или немного больше, то такое значение придётся признать нетипично высоким для совпадающих долей (пп. 2 – 4 таблицы 2), но оно остаётся достаточно типичным для случая с заранее заданными разными вероятностями «успеха» в двух группах этого объёма. Далее, при значениях 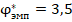 и выше до максимально возможного значения
и выше до максимально возможного значения 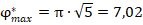 , наблюдаются значения, нетипично высокие для обеих ситуаций: и с заранее заданной одинаковой вероятностью «успеха» в двух группах, и для различающейся. То есть можно заключить, что различие в долях отражает более яркое различие в вероятностях «успеха» в группах, чем между 0,1 и 0,3 (либо при сборе данных произошла какая-то серьёзная ошибка).
, наблюдаются значения, нетипично высокие для обеих ситуаций: и с заранее заданной одинаковой вероятностью «успеха» в двух группах, и для различающейся. То есть можно заключить, что различие в долях отражает более яркое различие в вероятностях «успеха» в группах, чем между 0,1 и 0,3 (либо при сборе данных произошла какая-то серьёзная ошибка).
Заметим, что «ошибка второго рода», то есть шансы ошибочно признать ситуации с различными вероятностями «успеха», схожими между собой по этому параметру, оказались малы из-за аккуратной традиционной формулировки вывода в -критерии: отсутствие данных за различие выборок не даёт основания признавать выборки схожими без специального дополнительного исследования - надо задуматься о том, какие параметры (разные вероятности «успеха» в группах) должны считаться неприемлемыми, и статистически исключить такую ситуацию по причине нетипично малого значения , что не входит в традиционный алгоритм использования -критерия.
В таблице 3, с целью взаимного сравнения, приведены значения , соответствующие некоторым квантилям в ситуациях с заданным объёмом сопоставляемых групп, типичным для исследований в педагогике, и разными заранее заданными вероятностями «успеха»: 0,1 и 0,5 в обеих группах, 0,1 в одной и 0,5 в другой группе. Интерпретация результатов дана ниже.
Таблица 3
Параметры распределений (квантили) случайной величины
|
|
|
|
|
|
|
|
|
|
1,44-2,08-2,08 1,38-1,85-2,10 1,44-2,36-3,52 |
1,31-2,05-2,31 1,31-1,68-2,10 1,75-4,31 |
1,89-2,10-2,33 1,31-1,70-2,08 1,87-4,51 |
1,94-2,15-2,25 1,35-1,74-2,07 1,97-4,65 |
|
|
|
|
|
1,48-1,89-2,50 1,31-1,60-2,10 1,60-4,58 |
1,33-1,75-2,32 1,33-1,66-2,10 3,31-5,2 |
1,32-1,80-2,28 1,29-1,7-2,02 3,60-5,4 |
1,34-1,74-2,31 1,29-1,67-2,00 3,79-5,7 |
1,37-1,72-2,28 1,39-1,68-2,00 4,01-5,9 |
|
|
|
|
1,35-1,75-2,09 1,29-1,66-2,03 4,30-6,0 |
1,36-1,66-1,98 1,28-1,68-1,97 4,80-6,5 |
1,31-1,68-2,05 1,28-1,67-1,98 5,3-7,0 |
1,32-1,71-2,04 1,28-1,66-1,99 5,8-7,5 |
|
|
|
|
|
1,29-1,71-2,1 1,35-1,65-1,96 5,5-7,2 |
1,31-1,69-2,01 1,29-1,65-1,98 6,2-7,9 |
1,31-1,67-2,01 1,29-1,66-1,97 6,9-8,6 |
|
|
|
|
|
|
1,30-1,64-2,00 1,28-1,63-1,97 7,3-9,0 |
1,30-1,67-2,00 1,27-1,67-1,95 8,5-11,0 |
|
|
|
|
|
|
|
1,30-1,65-1,98 1,31-1,64-1,97 10,6-12,3 |
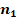
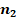
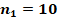
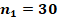
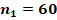
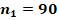
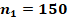
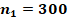
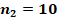
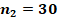
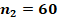
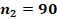
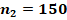
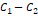
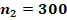
Для двух сопоставляемых групп с указанными в заголовках объёмами и и заранее заданной вероятностью «успеха» 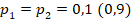 с доверительной вероятностью 0,8, 0,9 или 0,95 не характерны значения , превышающие
с доверительной вероятностью 0,8, 0,9 или 0,95 не характерны значения , превышающие 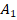 ,
, 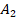 или
или 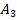 соответственно, а при
соответственно, а при 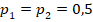 критические значения
критические значения 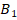 ,
, 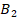 или
или 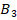 ; если заметно превышает указанные критические значения – можно утверждать, что сопоставляемые группы различаются по частоте «успеха».
; если заметно превышает указанные критические значения – можно утверждать, что сопоставляемые группы различаются по частоте «успеха».
Для заранее заданных вероятностей успеха 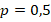 в одной группе и
в одной группе и 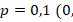 9) в другой группе менее 20% реализаций показывают значение меньше
9) в другой группе менее 20% реализаций показывают значение меньше 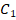 , и менее 20% реализаций – более
, и менее 20% реализаций – более 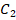 ; если заметно превышает указанные критические значения – можно утверждать, что сопоставляемые группы различаются по частоте «успеха» значительней, чем эти заранее заданные вероятности, либо при фиксации и обработке эмпирических данных допущены ошибки.
; если заметно превышает указанные критические значения – можно утверждать, что сопоставляемые группы различаются по частоте «успеха» значительней, чем эти заранее заданные вероятности, либо при фиксации и обработке эмпирических данных допущены ошибки.
Если зафиксировать объём одной из сопоставляемых групп и рассмотреть критические значения, соответствующие квантилям распределений, в зависимости от объёма второй группы, то значения , характерные и критические для различающихся заранее заданных вероятностей «успеха» в сопоставляемых группах, устойчиво возрастают, а рассчитанные критические значения в ситуациях с одинаковыми заранее заданными вероятностями демонстрируют более сложную картину (рис. 3). При объёме хотя бы одной из сопоставляемых групп до 30 случаев критические значения слабо предсказуемы, но не превышают значения 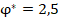 , сказывается дискретность распределений. Если объёмы обеих сопоставляемых групп от 60 случаев, то критические показатели распределений оказываются достаточно стабильными. На рисунке 3 отдельно цветом показаны эти два типа ситуаций, а данные для 300 случаев в одной из групп выделены отдельно и показаны чёрным пунктиром.
, сказывается дискретность распределений. Если объёмы обеих сопоставляемых групп от 60 случаев, то критические показатели распределений оказываются достаточно стабильными. На рисунке 3 отдельно цветом показаны эти два типа ситуаций, а данные для 300 случаев в одной из групп выделены отдельно и показаны чёрным пунктиром.
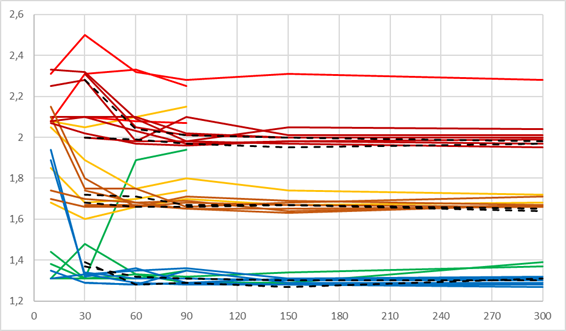
Рис. 3. Динамика критических значений при фиксированном значении объёма одной группы и одинаковой заранее заданной вероятности «успеха»
Практические рекомендации
1. Несмотря на сложности в применении, не указанные в традиционном алгоритме применения, полностью отказываться от углового преобразования не надо, так как оно сближает между собой показатели при сопоставлении групп объёмом от 60 случаев в каждой. Наоборот, можно утверждать, что значение 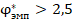 свидетельствует о различной вероятности «успеха» в группах (без уточнения, насколько велика эта разница) с доверительной вероятностью не менее 95%.
свидетельствует о различной вероятности «успеха» в группах (без уточнения, насколько велика эта разница) с доверительной вероятностью не менее 95%.
2. Лучший способ применения углового преобразования – точное аналитическое моделирование случайной величины (процедура описана выше) для тех объёмов сопоставляемых групп, возможных (совпадающих или различных, по логике проводимого исследования) вероятностей «успеха», оно позволяет ответить на вопрос, насколько типично для этих гипотетических значений.
3. Возможно использование рассмотренных в таблице 3 ситуаций и критических значений, приведённых в ней, для этого надо выбрать одно или несколько близких по объёму групп позиций и качественно обобщить выводы.
4. Выводы, сделанные с помощью малых по объёму групп и в ситуациях, когда частота успеха менее 0,1, являются ненадёжными, и -критерий не способен чудесным образом изменить это. Для научного педагогического обобщения лучше отказаться от сопоставления групп менее 60 индивидуальных случаев. Примером сомнительного использования φ*-критерия может служить [21], где сопоставлялись группы объёмом от 2 до 15 случаев.
5. Материалы статьи могут быть использованы как основа для лабораторной работы по основам статистики в образовательной практике вузов.
Пример
Студенты специальности «Эксплуатация железных дорог» ФГБОУ ВО «Уральский государственный университет путей сообщения» каждый семестр изучения курса математики заканчивают тестированием с использованием материала Единого портала интернет-тестирования в сфере образования [22]. Для выявления особенностей влияния вынужденного перехода к дистанционным формам взаимодействия были сопоставлены данные студентов до этого перехода и после него по трём показателям успешности: доля допущенных студентов от общего списочного состава, доля успешных (зачтённых) случаев тестирования среди допущенных и в общем списочном составе. Симметрия расчётной процедуры -критерия позволила использовать его для значений долей «успеха» в сопоставляемых группах (обобщённых потоках студентов), близких к 0,9, так же как для значений, близких к 0,1. Результаты представлены в таблице 4. В рассмотренном примере оказалось, что доля студентов, вовремя допущенных к первому массовому тестированию, заметно уменьшилась при введении дистанционных форм взаимодействия. Однако резко возросшая результативность тестирования (которое тоже стало проводиться дистанционно) не только компенсировала эти потери, но даже показала некоторое увеличение успеваемости по результату теста в общем списочном составе.
Таблица 4
Сопоставление успешности тестирования студентов при введении дистанционных форм педагогического взаимодействия
|
Показатель |
Зимняя сессия 2019/20 уч. года |
Летняя сессия 2019/20 уч. года |
|
|
Общее количество студентов |
176 |
352 |
|
|
Допущено к первому массовому тестированию |
159 |
266 |
|
|
Успешно прошли тест |
105 |
237 |
|
|
Доля (от общего количества) допущенных к тесту студентов |
0,90 |
0,76 |
4,35* |
|
Доля (от допущенных) студентов, успешно прошедших тест |
0,66 |
0,89 |
5,74** |
|
Доля (от общего количества) студентов, успешно прошедших тест |
0,60 |
0,67 |
1,73*** |
* близкие данные таблицы 2 для 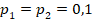 в группах объёма
в группах объёма 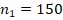 и
и 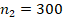 , в сравнении со значением
, в сравнении со значением 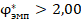 , позволяют утверждать, что сопоставляемые группы различаются по доле «успеха» с доверительной вероятностью не менее чем 95% (на уровне значимости менее 5%). С другой стороны, фактические значения
, позволяют утверждать, что сопоставляемые группы различаются по доле «успеха» с доверительной вероятностью не менее чем 95% (на уровне значимости менее 5%). С другой стороны, фактические значения 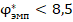 ожидаемо малы для яркого (как 0,1 и 0,5) различия долей. Точное моделирование для данных объёмов групп и успешности показывает, что такое значение характерно для реализации случайной величины с заранее заданными вероятностями успеха
ожидаемо малы для яркого (как 0,1 и 0,5) различия долей. Точное моделирование для данных объёмов групп и успешности показывает, что такое значение характерно для реализации случайной величины с заранее заданными вероятностями успеха 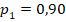 и
и 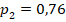 (58% случаев показывают менее этого значения, 42% – больше). А для усреднённого по выборкам значения
(58% случаев показывают менее этого значения, 42% – больше). А для усреднённого по выборкам значения 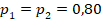 это значение оказывается нехарактерно высоким (99% реализаций демонстрируют значение
это значение оказывается нехарактерно высоким (99% реализаций демонстрируют значение 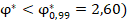 , всё это подтверждает предшествующий вывод о различии двух сопоставляемых групп;
, всё это подтверждает предшествующий вывод о различии двух сопоставляемых групп;
** близкие данные таблицы 2 для в группах объёма и , в сравнении со значением , позволяют утверждать, что сопоставляемые группы различаются по доле «успеха» с доверительной вероятностью не менее чем 95% (на уровне значимости менее 5%). С другой стороны, фактические значения ожидаемо малы для яркого (как 0,1 и 0,5) различия долей. Точное моделирование для данных объёмов групп и успешности показывает, что такое значение характерно для реализации случайной величины с заранее заданными вероятностями успеха 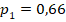 и
и 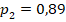 (52% случаев показывают менее этого значения, 48% – больше). А для усреднённого по выборкам значения
(52% случаев показывают менее этого значения, 48% – больше). А для усреднённого по выборкам значения 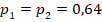 это значение оказывается нехарактерно высоким (99% реализаций демонстрируют значение , всё это подтверждает предшествующий вывод о различии двух сопоставляемых групп;
это значение оказывается нехарактерно высоким (99% реализаций демонстрируют значение , всё это подтверждает предшествующий вывод о различии двух сопоставляемых групп;
*** близкие данные таблицы 2 для в группах объёма и , в сравнении со значением 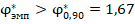 (но
(но 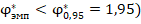 , позволяют утверждать, что сопоставляемые группы совпадают либо слабо различаются по доле «успеха» с доверительной вероятностью не менее чем 90% (на уровне значимости менее 10%). Точное моделирование для данных объёмов групп и успешности показывает, что такое значение характерно для реализации случайной величины с заранее заданными вероятностями успеха
, позволяют утверждать, что сопоставляемые группы совпадают либо слабо различаются по доле «успеха» с доверительной вероятностью не менее чем 90% (на уровне значимости менее 10%). Точное моделирование для данных объёмов групп и успешности показывает, что такое значение характерно для реализации случайной величины с заранее заданными вероятностями успеха 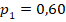 и
и 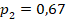 (56% случаев показывают менее этого значения, 44% – больше). А для усреднённого по выборкам значения это значение оказывается довольно высоким (91% реализаций демонстрируют значение менее , 9% – больше), всё это подтверждает предшествующий вывод о совпадении либо слабом различии двух сопоставляемых групп.
(56% случаев показывают менее этого значения, 44% – больше). А для усреднённого по выборкам значения это значение оказывается довольно высоким (91% реализаций демонстрируют значение менее , 9% – больше), всё это подтверждает предшествующий вывод о совпадении либо слабом различии двух сопоставляемых групп.
Заключение
Использование углового преобразования для сопоставления групп может принести значительную пользу в прикладных и научных педагогических задачах. Проведённое исследование уточнило границы применимости и особенности применения этого приёма. Для «сверхбыстрого» решения о различии двух групп по доле «успеха» можно пользоваться значением 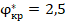 , более детальное понимание ситуации достигается использованием табличных данных или точным моделированием ситуации.
, более детальное понимание ситуации достигается использованием табличных данных или точным моделированием ситуации.